Amazônia president’s tour to Italy to present her book “Amazzonia. Una vita nel cuore della foresta” (Editori Laterza) has just ended.
The author declares, “In the book I tried to tell about the humanity and the spaces that make this heterogeneous place one of the most fascinating on the planet, the beauty of the territories and its inhabitants, not only human, as well as the fear and the enchantment that spring from the unmediated contact with nature. But also violence, illegal mining, logging, speculation, poaching, the struggle of the natives in defense of the forest. The book is meant to be my personal contribution to the debate on the environmental issue and the current and future challenges the planet is facing.”
Emanuela’s tour touched numerous Italian cities, including Milan, Lucca, Florence, and Rome, but also reserved a special space in Lanuvio, the biologist’s hometown. During this tour, the audience had the opportunity to immerse themselves in the depths of the Amazon rainforest through Emanuela’s engaging descriptions. In addition, the tour offered a valuable opportunity to learn firsthand about the significant work done by the Amazônia Association in preserving and protecting this extraordinary and vital part of our planet. The book was so successful that it was reprinted only thirty days after its debut in bookstores.
Between October and December Emanuela gave several interviews and participated in numerous radio and television broadcasts, emphatically stressing the importance and urgency of pursuing the construction of a model of society based on criteria of greater responsibility in the social, environmental and economic spheres.
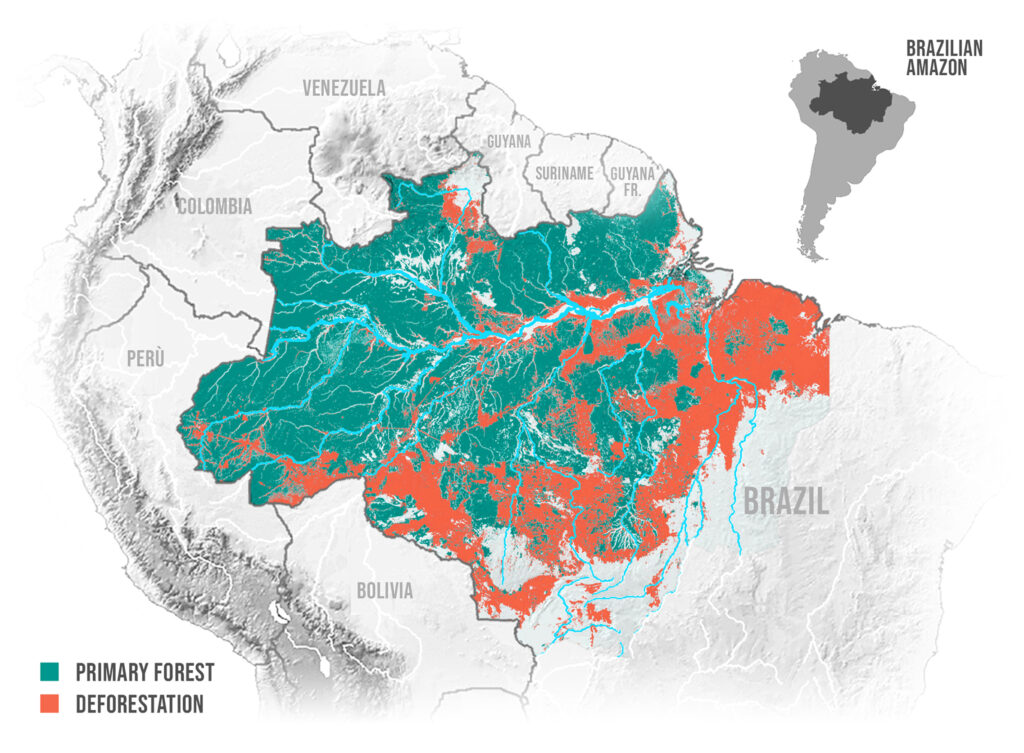
During her public appearances, she did not fail to highlight the current situation of extreme and unprecedented drought afflicting the Amazon and forest peoples, with devastating consequences for the ecosystem and the communities̀ that depend on the forest and rivers for subsistence.
Together with partner Amazon Charitable Trust Emanuela also attended COP 28 in Dubai, closely following the negotiations at the UN World Climate Conference. This important event discussed the fate of our planet and possible solutions to counter the growing climate crisis.



Pianeta Terra Festival, Lucca
Camera dei Deputati, Roma
Marostica, Centro Culturale



BookCity, Milano
Festival L’Eredità delle Donne, Firenze
Fiera Più Libri, Più Liberi



Quante storie, RAI 3
Alla scoperta del Ramo d’Oro, RAI 3
La Forza delle Donne, Uno Mattina RAI 1

Click here for the book details and to purchase ‘Amazzonia. Una vita nel cuore della foresta'(In Italian)
Click here for articles, interviews, radio and TV appearances
List of appointments on the book presentation tour:
8/10 – Lucca – Festival Pianeta Terra, in dialogo con Alessandra Viola.
15/10 – Reggio Emilia – Festival Finalmente Domenica, Dialogo con Davide Papotti. Ridotto del Teatro Valli.
16/10 – Borgomanero – Oratorio di Borgomanero, in collaborazione con PIME.
23/10 – Roma – Camera dei Deputati, Sala Matteotti, Piazza del Parlamento 19. Saluti Istituzionali: On. Andrea Volpi (Deputato della Repubblica), On. Fabio Porta (Deputato della Repubblica). Moderato da Stefano Zago (Direttore Teleambiente); Interventi di Simone Santilli (Assessore all’Ambiente – Lanuvio), Pierluigi Sassi (Presidente di Earth Day Italia).
28/10 – Albano Laziale – Le Promesse Libreria Bistrot, in dialogo con Francesca Guercio.
7/11 – Lanuvio (RM), Sala delle Colonne Villa Sforza Cesarini, in dialogo con Antonella Rizzo. Interventi del Sindaco di Lanuvio on. Andrea Volpi e del Presidente del Consiglio Comunale Alessandro De Santis.
10/11 – Roverè della Luna (TN), Circolo Culturale Ricreativo.
12/11 – Marostica (VI), Centro Culturale ex Chiesetta San Marco, a cura di ASD Progetto Sport e Cultura.
13/11 – Cartigliano (VI), Villa Morosini Cappello, a cura di ASD Progetto Sport e Cultura.
14/11 – Modena, Sede Foreste per Sempre ODV – Gev Modena.
16/11 – Brescia, Nuova Libreria Rinascita, in dialogo con Giovanni Mori (Fridays For Future).
17/11 – Bergamo, Libreria Incrocio Quarenghi.
18/11 – Milano, Fabbrica del Vapore, nell’ambito di BookCity Milano, in dialogo con Daria Bignardi.
25/11 – Firenze, Festival L’Eredità delle Donne, Manifattura Tabacchi, Sala Ridotto, in dialogo con il Edoardo Vigna.
10/12 – Roma, Fiera Più Libri, Più Liberi, in dialogo con Paolo Di Paolo.